Research discovery
Has someone answered that question I have not worked out how to ask yet?
January 22, 2019 — March 26, 2024

Recommender systems for academics are hard and in particular, I suspect they are harder than normal recommender systems because definitionally the content should be new and hard to relate to existing stuff. Indeed, finding connections is a publishable result in itself. Hard-nosed applied version of the vageuly woo-woo idea of knowledge topology.
Complicated interaction with systems of peer review. Could this integrate with peer review in some useful way? Can we have services like Canopy, Pinterest or keen for scientific knowledge? How can we trade of recall and precision for the needs of academics?
Moreover the information environment is challenging. I am fond of Elizabeth Van Nostrand’s summary::
assessing a work often requires the same skills/knowledge you were hoping to get from said work. You can’t identify a good book in a field until you’ve read several. But improving your starting place does save time, so I should talk about how to choose a starting place.
One difficulty is that this process is heavily adversarial. A lot of people want you to believe a particular thing, and a larger set don’t care what you believe as long as you find your truth via their amazon affiliate link […] The latter group fills me with anger and sadness; at least the people trying to convert you believe in something (maybe even the thing they’re trying to convince you of). The link farmers are just polluting the commons.
My paraphrase: knowledge discovery would likely be intrinsically difficult in a hypothetical beneficent world with great sharing mechanisms, but the economics of attention, advertising and weaponised media mean that we should be suspicious of the mechanisms that we can currently access.
If I accept this, then the corollary is that my scattershot approach to link sharing is possibly detracting from the value of this blog to the wider world.
1 Theory
José Luis Ricón, a.k.a. Nintil, wonders about A better Google Scholar based in experience trying to make a better Meta Scholar for Syntopic reading. Robin Hanson, of course, has much to say on potentially better mechanism design for scientific discovery. I have qualms about his implied cash rewards system crowding out reputational awards; I think there is something to be said for that particular economy using non-cash currency; but open to being persuaded.
2 Projects
2.1 scite
scite: see how research has been cited
Citations are classified by a deep learning model that is trained to identify three categories of citation statements: those that provide contrasting or supporting evidence for the cited work, and others, which mention the cited study without providing evidence for its validity.Citations are classified by rhetorical function, not positive or negative sentiment.
- Citations are not classified as supporting or contrasting by positive or negative keywords.
- A Suppporting citation can have a negative sentiement and a Contrasting citation can have a positive sentiement. Sentiment and rhetorical function are not correlated.
- Supporting and Contrasting citations do not necessarily indicate that the exact set of experiments were performed. For example, if a paper finds that drug X causes phenomenon Y in mice and a subsequent paper finds that drug X causes phenomenon Y in yeast but both come to this conclusion with different experiments—this would be classified as a supporting citation, even though identical experiments were not performed.
- Citations that simply use the same method, reagent, or software are not classified as supporting. To identify methods citations, you can filter by the section.
For full technical details including exactly how we do classification, what classifications and classification confidence means please read our recent publication describing how scite was built: (Nicholson et al. 2021)/
2.2 Researchrabbit
- Spotify for Papers: Just like in Spotify, you can add papers to collections. ResearchRabbit learns what you love and improves its recommendations!
- Personalized Digests: Keep up with the latest papers related to your collections! If we’re not confident something’s relevant, we don’t email you—no spam!
- Interactive Visualizations: Visualize networks of papers and co-authorships. Use graphs as new “jumping off points” to dive even deeper!
- Explore Together: Collaborate on collections, or help kickstart someone’s search process! And leave comments as well!
2.3 Connectedpapers
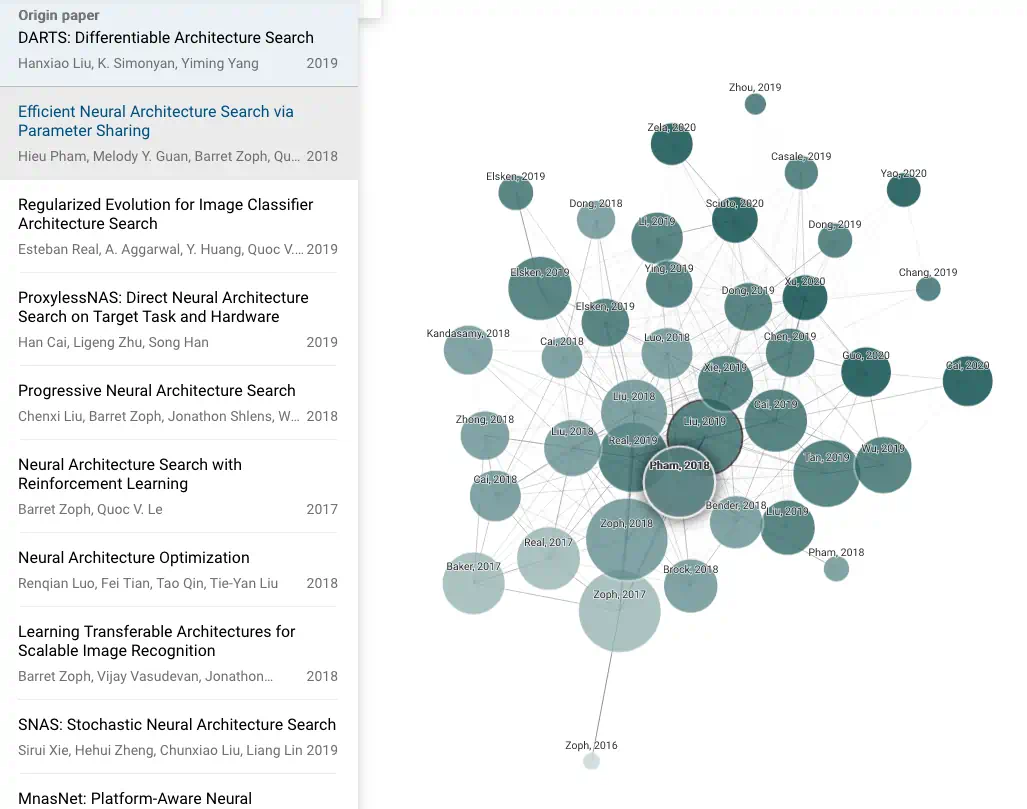
- To create each graph, we analyze an order of ~50,000 papers and select the few dozen with the strongest connections to the origin paper.
- In the graph, papers are arranged according to their similarity. That means that even papers that do not directly cite each other can be strongly connected and very closely positioned. Connected Papers is not a citation tree.
- Our similarity metric is based on the concepts of Co-citation and Bibliographic Coupling. According to this measure, two papers that have highly overlapping citations and references are presumed to have a higher chance of treating a related subject matter.
- Our algorithm then builds a Force Directed Graph to distribute the papers in a way that visually clusters similar papers together and pushes less similar papers away from each other. Upon node selection we highlight the shortest path from each node to the origin paper in similarity space.
- Our database is connected to the Semantic Scholar Paper Corpus (licensed under ODC-BY). Their team has done an amazing job of compiling hundreds of millions of published papers across many scientific fields.
Also:
You can use Connected Papers to:
Get a visual overview of a new academic field Enter a typical paper and we’ll build you a graph of similar papers in the field. Explore and build more graphs for interesting papers that you find—soon you’ll have a real, visual understanding of the trends, popular works and dynamics of the field you’re interested in.
Make sure you haven’t missed an important paper In some fields like Machine Learning, so many new papers are published it’s hard to keep track. With Connected Papers you can just search and visually discover important recent papers. No need to keep lists.
Create the bibliography for your thesis Start with the references that you will definitely want in your bibliography and use Connected Papers to fill in the gaps and find the rest!
Discover the most relevant prior and derivative works Use our Prior Works view to find important ancestor works in your field of interest. Use our Derivative Works view to find literature reviews of the field, as well as recently published State of the Art that followed your input paper.
2.4 Elicit
Elicit: The AI Research Assistant exploits large language models to solve this problem
Elicit uses language models to help you automate research workflows, like parts of literature review.
Elicit can find relevant papers without perfect keyword match, summarize takeaways from the paper specific to your question, and extract key information from the papers.
While answering questions with research is the main focus of Elicit, there are also other research tasks that help with brainstorming, summarization, and text classification.
2.5 papr
papr — “tinder for preprints”
We all know the peer review system is hopelessly overmatched by the deluge of papers coming out. papr reviews use the wisdom of the crowd to quickly filter papers that are considered interesting and accurate. Add your quick judgements about papers to those of thousands of scientists around the world.
You can use the app to keep track of interesting papers and share them with your friends. Spend 30 min quickly sorting through the latest literature and papr will keep track of the papers you want to come back to.
With papr you can filter to only see papers that match areas that interest you, keywords that match your interest, or papers that others have rated as interesting or high quality. Make sure your literature review is productive and efficient.
I appreciate the quality problem is important, but I am unconvinced by their topic keywords idea. Quality is only half the problem for me and the topic-filtering problem looks harder.
2.6 Daily papers
Daily Papers seems to be similar to arxiv-sanity but they are more actively maintained and less coherently explained. Their paper rankings seem to incorporate… twitter hype?
2.7 arxiv sanity
Aims (aimed?) to prioritise the arxiv paper-publishing firehose so that you can discover papers of relevance to your own interests, at least if those interests are in machine learning.
Arxiv Sanity Preserver
Built by @karpathy to accelerate research. Serving last 26179 papers from cs.[CV|CL|LG|AI|NE]/stat.ML
Includes twitter-hype sorting, TF-IDF clustering, and other such basic but important baby steps towards web2.0 style information consumption.
The servers are overloaded of late, possibly because of the unfavourable scaling of all the SVMs that it uses, or the continued growth of Arxiv, or epidemic addiction to intermittent variable rewards amongst machine learning researchers. That last reason is why I have opted out of checking for papers.
I could run my own installation — it is open source — but the download and processing requirements are prohibitive. Arxiv is big and fast.
2.8 trendingarxiv
Keep track of arXiv papers and the tweet mini-commentaries that your friends are discussing on Twitter.
Because somehow some researchers have time for twitter and the opinions of such multitasking prodigies are probably worthy of note. That is sadly beyond my own modest capacities. Anyway, great hack, good luck.
- Journal / Author Name Estimator identifies potential collaborators and journals by semantic similarity search on the abstract
- Grant matchmaker suggest people with similar grants inside the USA’s NIH
2.9 The syllabus
I wonder if this techno-editorial system works?
Each week we publish curated syllabi featuring pieces that cut across text, video and audio. The curation runs either along thematic lines — e.g. technology, political economy, arts & culture — or by media type such as Best of Academic Papers, Podcasts, Videos. You can also build your own personalised syllabus centered around your interests.
Our approach rests on a mix of algorithmic and human curation: each week, our algorithms detect tens of thousands of potential candidates — and not just in English. Our human editors, led by Evgeny Morozov, then select a few hundred worthy items.
It is run by a slightly crazy sounding guy, Evgeny Morozov.
The way in which Morozov collects and analyses information is secret, he says. He doesn’t want to expand on how he compares his taxonomies with the actual content of videos, podcasts, books and articles. “That’s where our cutting-edge innovation lies.”
… The categorisation and scoring of all information is an initial screening. Everything is then assessed by Morozov and his assistants, several times, ultimately resulting in a selection of the very best and most relevant information that appears during a week, sorted by theme.
I do not believe this solves a problem I personally face, but perhaps it solves a useful problem generally? I am somewhat bemused by the type of scientific knowledge diffusion process that this implies. Is converging on a canonical list of this week’s hottest think pieces what we can and/or should be doing?

3 Reading groups and co-learning
A great way to get things done. How can we make reading together easier?
The Journal Club is a web-based tool designed to help organize journal clubs, aka reading groups. A journal club is a group of people coming together at regular intervals, e.g., weekly, to critically discuss research papers. The Journal Club makes it easy to keep track of information about the club’s meeting time and place as well as the list of papers coming up for discussion, papers that have been discussed in previous meetings, and papers proposed by club members for future discussion.
4 Paper analysis/annotation
5 Finding copies
unpaywall and oadoi seem to be indices of non-paywalled preprints of paywalled articles. oadoi is a website, unpaywall is a browser extension. Citeseer also.