Data summarization
On maps drawn at smaller than 1:1 scale
January 14, 2019 — February 8, 2024

Summary statistics which don’t require us to keep all the data but which allow us to nonetheless do inference nearly as well. e.g sufficient statistics in exponential families allow you to do certain kind of inference perfectly without anything except summaries. Methods such as variational Bayes summarize data by maintaining a posterior density as a summary of all the data likelihood, at some cost in accuracy. I think of these as nearly sufficient statistics but we could thinkg of these data summarization which I note here for later reference.
- Approximate Bayesian Computation
- inducing sets, as seen in Gaussian processes
- coresets as seen in Bayesian models
- probabilistic deep learning possibly does this
- Bounded Memory Learning considers this from a computational complexity standpoint — is that related?
- Some dimension reductions are data summarization
TBC.
1 Bayes duality
2 Coresets
Bayesian. Solve an optimisation problem to minimise distance between posterior with all data and with a weighted subset.
3 Representative subsets
I think this is intended to be generic? See apricot:
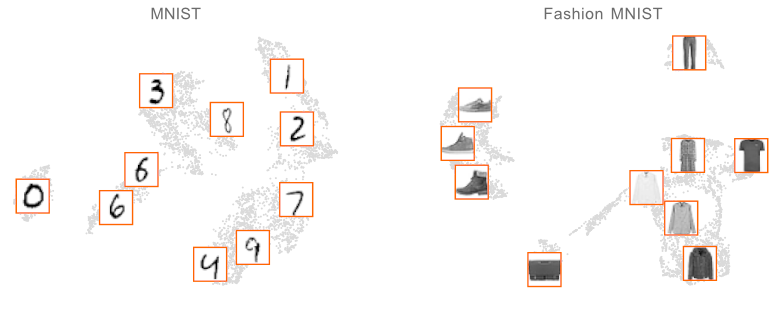
apricot implements submodular optimization for the purpose of summarizing massive data sets into minimally redundant subsets that are still representative of the original data. These subsets are useful for both visualizing the modalities in the data (such as in the two data sets below) and for training accurate machine learning models with just a fraction of the examples and compute.
4 By influence functions
Including data based on how much it changes the predictions. Classic approach (Cook 1977; Thomas and Cook 1990) for linear models. Can be applied also to DL models. A bayes-by-backprop approach is Nickl et al. (2023), and a heroic second-order method is Grosse et al. (2023).
